
何かと話題のAIイラスト環境を構築してみました。手軽に環境が作れるなんて良い時代になりましたね…。
AIイラスト作成に必要なもの
グラボ搭載のWindowsPCであれば出力自体は問題なさそう。機械学習するとか、ハイレゾ出力したいとかだとグラフィックメモリを多用するため、そこそこ良いグラボがないと無理っぽいです。
私の環境は古めで GeForce GTX1060 ですが、6GBモデルなのでギリギリ出力できるって感じ。3GBモデルだったらキツそう…。
「環境がないよ」って人はGoogle Colabを使うか、月額課金制のNovelAI使いましょう。


自分のPC上に構築したらぜんぶタダで出来ちゃいます。Windowsでそこそこのグラボ(GeForce系)を持っているなら自PC上に構築をオススメします!自分の好きなタイミングで何回でも作成できますし。
Stable Diffusion の導入
いよいよ導入ですが、開発経験者ならサクッといけると思います。相当端折って書きますと…
- Python 3.10.6 のインストール
- gitのインストール
- GitHubからソースをクローンする
- モデルの入手
- 初回起動
となります!
いずれも現時点(2023年3月23日)の情報で、この界隈は非常にアップデートが頻繁なのでやり方変わる可能性があることはご注意ください…。
1.Python 3.10.6 のインストール
バージョン指定があることに注意!まぁ新しいバージョンでも動くんだろうけど、作者がこれって指示してるので不要な不具合とか発生させないためにもバージョンは合わせておきましょう。
インストール時にパスを通すことをお忘れなく!
2.git のインストール
開発者なら既にインストール済みかも知れませんが、Stable Diffusion のソースをコピーするのに使います。

3.GitHub からソースをクローンする
任意のフォルダで良いですが、オススメはSSDで30GBくらい空き容量があったほうが良いです。後述の「モデル」が1つ5GBくらいするので、余裕あったほうが良いのと、HDDじゃ遅すぎてストレスマッハです。
(ちなみに作画したデータは1枚1MB程度なので気にするほどでもないかと)
私はDドライブ(SSD)に「AI」フォルダを作ってクローンしました。当然ですがフォルダパスに日本語など2バイト文字が入らないようにしましょう…
クローンするGitHubソースはこちら↓

gitコマンドはこんな感じで。
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
4.モデルの入手
Stable Diffusion は「モデル」を使ってAIイラストを作成します。ベースのようなもので、モデルによって得意不得意があったり、出力される絵柄が変わります。実写系だったり、マンガ風だったり…。
初回起動前に何かしらモデルを導入しとかないと起動に失敗するので、適当なモデルを入手しておきます。もちろん後から追加もできますし、好みのモデルを探す旅は初回起動後でOKです。
まずは王道の Anything V4 を導入します。

この「Files and versions」のリストからダウンロード…なんですが、めちゃくちゃファイルが多くてどれやねん!ってなります。
基本的には拡張子が「.safetensors」のものを選んでおけばOKです。これがだいたい5GBくらいあるんですよね…なので、モデルをたくさんダウンロードするとどんどん容量が圧迫されます…。
まずはお試し的に「anything-v4.0-pruned.safetensors」をダウンロードして、先ほどクローンした [\stable-diffusion-webui\models\Stable-diffusion]フォルダにコピーしましょう。
これで基本的な準備は完了です!
5.初回起動
[\stable-diffusion-webui]フォルダにある「webui-user.bat」を起動させましょう。初回はけっこう時間かかるのでしばらく待機…。(2回目以降は早いです)
しばらくすると「Running on local URL: http://127.0.0.1:7860」と表示が出て(その下にもいろいろ出てると思いますが)止まれば準備完了!ブラウザで http://127.0.0.1:7860 を開きましょう。基本的にポートも変わらないので、お気に入りに入れといても良いし、webui-user.bat のコマンドラインで自動的に開くこともできます。
AIイラストを出力してみる
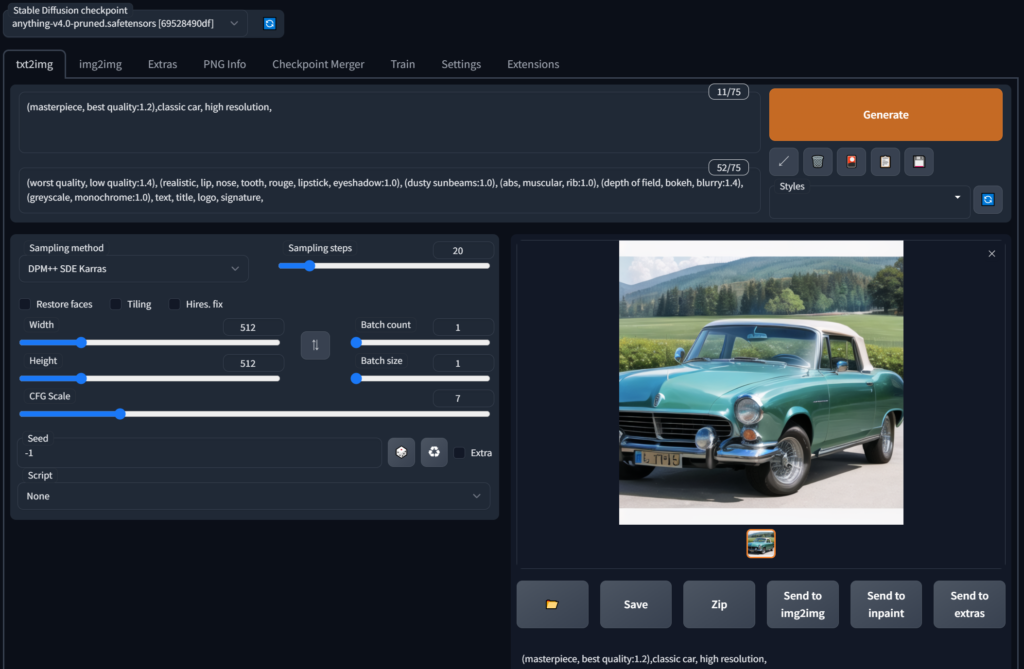
ブラウザで開いてみるとシンプルなUIが立ち上がります。
左上の「Stable Diffusion checkpoint」というところに、導入したモデルが表示されていればOKです!選択肢に出てこない場合はコピー先を確認してみましょう。
簡単に画面の説明
まず触るところは「txt2img」タブだけでOKです。上の方にあるコマンドラインは後述するとして、中断らへんの数値やらについて説明します。
| Sampling method | 描画モードのようなもんです。大量にありますが、これもモデルによってオススメがあるので参考に…。個人的にはDPM++ SDE Karrasをよく使ってます。 |
| Sampling steps | 何回計算するか指定します。AIはボヤけた画像から徐々にカタチを整えるので、その回数です。お試しなら10回くらい、本番なら20回以上がオススメです。回数が多ければその分時間がかかりますし、多ければ良いというわけでもありません。 |
| Restore faces, Tiling, Hires.fix | それぞれオプションですが今は気にしなくてOKです。 |
| Width, Height | 出力する画像サイズです。基本的に512×512でAIは考えているようなので、比率を変えるとクリーチャーが生まれやすくなります。ちょっと縦長(横長)くらいで抑えておきましょう。もちろん解像度が高ければそれだけ処理に時間がかかります。(グラボがショボければ失敗する可能性も) |
| Batch count | 同じ条件で何回実行するか指定できます。 |
| Batch size | 1回で何枚出力するか指定できます。複数枚にするとそれだけグラボのメモリを消費します。 |
| CFG Scale | 後述の呪文にどれほど忠実に従うか指定します。数字が大きければより呪文に忠実になりますが、指示していない箇所が崩れやすくなります。だいたい7~10が推奨のようです。 |
| Seed | 出力したらシード値が払い出されます。同じシード値を指定することで、似たような条件で出直されます。-1を指定したら毎回違うシード値(毎回新規)で作成されます。 |
| Script | 追加スクリプトですが今は気にしなくてOKです。 |
最重要!プロンプトについて
AIイラストの最重要ポイント、それがプロンプトです。ちまたでは呪文とか言ったりします。
要はAIに「こういう絵を描いてね」と指示する構文のことで、ポジティブプロンプトとネガティブプロンプトに分かれます。
ポジティブプロンプトとは、文字通り「こういう絵を描いて欲しい」というお願いをするところです。逆にネガティブプロンプトとは、「こういう絵は描かないでね!」と指示します。
例えば美少女キャラを描いて欲しいとだけ指示すると、職場閲覧不可な画像が出力されることが(よく)あります。こういう時にネガティブワードに追加しておくと抑制される…という使い方をします。
書き方は英語で文章でもOK
(masterpiece, best quality:1.2),classic car, high resolution, こんな感じで書いていきます。ワードをカンマ区切りで表現し、文章でもOKです。原則、左から優先されていきます。()は強調で、コロンの後の数字が倍率です。例えば上記では「masterpieceとbest qualityの適用度合いを1.2倍にする」という呪文です。
(worst quality, low quality:1.4), (realistic, lip, nose, tooth, rouge, lipstick, eyeshadow:1.0), (dusty sunbeams:1.0), (abs, muscular, rib:1.0), (depth of field, bokeh, blurry:1.4), (greyscale, monochrome:1.0), text, title, logo, signature,ネガティブワードはこんな感じで…書き過ぎても良くないんですが、モデルによって最適解が変わるので、モデルを提供している開発者がオススメの設定などをコピーしましょう。
実際に出力した結果

上記の通り、ポジティブプロンプトに「classic car」と指示したので、良い感じのレトロな車が出力されました。ちなみに指示していない箇所はAIが勝手に補完します。なので、草原?山?にあるのはAIさんが勝手に考えて描いたってことですね。
では、背景は砂浜が良いので「sandy beach」を追加してみます。

するとこんな感じで砂浜にクラシックカーが!(車変わってますけど)
このように文字で指示するだけでイラストが出力される、ということができるようになりました。いやぁ…AIすごいね。
奥が深い世界
このように、そこそこのWindowsPCがあれば誰でもAIイラストが描ける時代になりました。
もちろん、今回はとりあえず出力するところまでなので、まだまだ深い設定が存在します。呪文の書き方もそうだし、モデルの選び方や今回触れてませんがVAEのこだわり、LoRAで機械学習などなど…。
日々新しいものが生まれ進化していくので、触って覚えたときにはもう新バージョンなんてことも…。とはいえ、触れなければ理解もできないので新しい技術にはどんどんタッチアンドトライしていきましょう!



コメント